Say you want to predict what to do next to get just that little bit further in your pursuit. Wouldn’t it be nice if you could learn from history to help make a slightly better decision?
Well…this is where next best action prediction comes in. You can leverage previous event history to help you forecast the next best thing to do.
This tutorial does exactly that and goes through:
- How to preprocess your event data
- Build a LSTM tensorflow model to predict events
- Generating the next best action in order to drive progress
Want to learn how to do it?
Keep following on and let’s kick it off.
1. Import data
We’re going to be working within Watson Studio for this example. So…if you haven’t done so already the first step is to load up your data into a new project. From within Watson Studio, choose the data menu and select Browse to upload the CSV file. The data used for this example can be found in this github repo.
Once you’ve uploaded the data you’re able to bring it into a new notebook by choosing selecting the data menu tab and selecting insert pandas DataFrame. This will automatically load in your data and create a Pandas DataFrame.

2. Preprocess data
Now that you’ve got some data loaded into your project it’s time to get cracking and get into some data munging. In order to predict the next event you’re going to need two key things, an event dictionary (in this case list) ANNNND sequences of events that have been one-hot-encoded. This will allow us to easily work with it and Tensorflow once we get to modelling.
First up, creating the list of events. Looking at the sales progression activities, we can see that we’ve got action type and action stages stored in two separate columns. The stage is important as it tells you how far the opportunity is from becoming a closed sale. So that you can retain this mapping in the dictionary, append these two together to create a stage/action column.
# Create neater event names df['Event Key'] = df['Stage'].astype(str) +'-'+ df['Action']
The next step is to create a unique list of events.
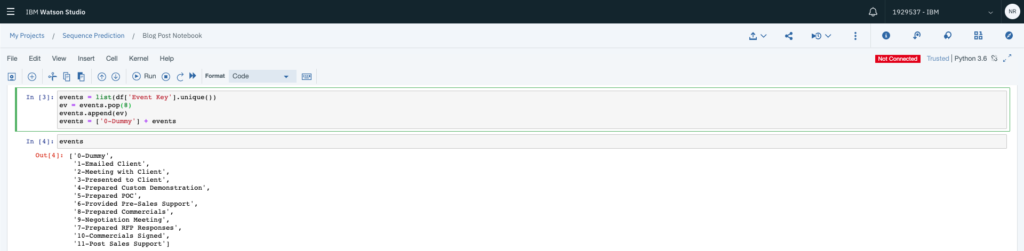
# Get unique events events = list(df['Event Key'].unique()) # Reorder the events to push stage 11 down ev = events.pop(8) events.append(ev) # Create a dummy event as the placeholder for stage 0 events = ['0-Dummy'] + events
You should end up with a list of values that looks a little like this.
Once you’ve predicted the action later, you’ll have an encoding which is a one-hot-encoded array that represents the stages. You’ll be able to use this list and a simple argmax function to convert the one-hot-encoded predictions to its text based equivalent.
3. Create time sequences
Right now you have a dataframe that looks a little like this. The data is pre sorted by Opportunity, Time and then Stage.
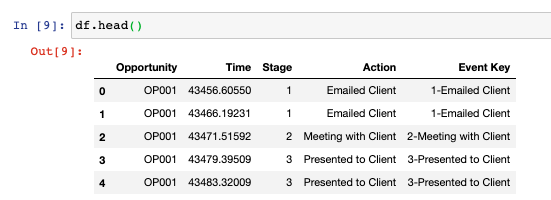
In order to work with it for sequence prediction, you have to reshape it into groups of sequences. In this case, we’ll use the four preceding events to predict the next most likely event.
So if we can use the historical events to help us predict what is most likely to happen next. In order to do this you need to reshape the data in order to create sets of sequences. The numpy.reshape and keras.utils.to_categorical functions can help make this a whole lot easier.
First create sequences of five preceding events.
# Specify parameters to use
# N.B. You can change the sequence length here
series_length = 5
categories = len(events)
time_steps = series_length -1
# Set index to use .loc
df.set_index('Opportunity', inplace=True)
# Create sequences - stored in the history variable
history = []
for op in df.index:
for x in range(len(df['Stage'].loc[op].values)-series_length):
history.append(df['Stage'].loc[op].values[x:x+series_length])
This will give you an array that looks something similar to what you see below with the same shape.
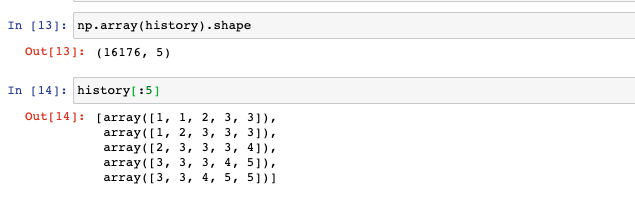
The next step is to turn this from index values, aka 1,2,2 to their one-hot-encoded equivalent aka [0,1,0,0,0],[0,0,1,0,0],[0,0,1,0,0]. This is where the Keras to_categorical function comes in.
# Import keras utils from tensorflow.keras.utils import to_categorical # Create input and one-hot X= np.array([row[:time_steps] for row in history]) X = to_categorical(X) # Create target and one-hot y=np.array([row[time_steps] for row in history]) y = to_categorical(y).reshape(-1,categories)
This will give you an input shape (X) which has the same number of observations, four sequences and 12 binary categories. It will also create a target variable (y) that has a matching number of observations and the same 12 binary categories.

4. Setup Tensorflow Model
Now the fun bit….modelling. To create this model you’ll create a deep neural network using LSTM and Fully Connected layers. But, first things first, let’s split our dataset into training and testing partitions.
# Import split function from sklearn.model_selection import train_test_split # Split the dataset with a 30% test size X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
Then we can start modelling, in this case you’ll stack two LSTM layers together and connect it all using a final fully connected layer. Feel free to experiment with different architectures that’s part of the fun with deep learning.
# Import tensorflow libs
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# Create a model instance
model = Sequential()
# Add the layers
model.add(LSTM(10, activation='relu', return_sequences=True, input_shape=(time_steps,categories)))
model.add(LSTM(10, activation='relu'))
model.add(Dense(categories, activation='softmax'))
# Build the graph
model.compile('adam', loss='categorical_crossentropy')
Assuming you did the same, you should have a model architecture that looks a little like this.

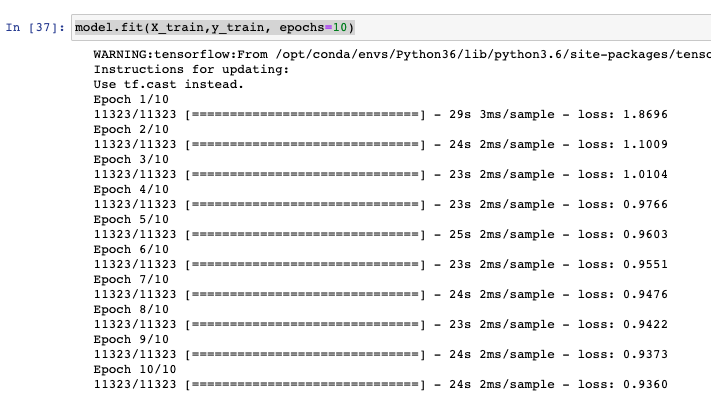
If that’s all good you can go ahead and kick off the training on the train partition.
# Train the model model.fit(X_train,y_train, epochs=10)
You should get to a loss of around .94ish.
5. Evaluate the model
To check the performance of the model you’re going to use the top_k_categorical_accuracy function. This will give compute how accurate the model was based on the top k predictions.
So if your model always picked the next event within the top 3 probabilities and we had k set to three, the accuracy returned would be 100%. More on top k accuracy here.
# Import tf to use sessions
import tensorflow as tf
from tensorflow.keras.metrics import top_k_categorical_accuracy
with tf.Session() as sess:
print('Correct event was top prediction:', top_k_categorical_accuracy(y_test,prediction, k=1).eval())
print('Correct event was in top two prediction:', top_k_categorical_accuracy(y_test,prediction, k=2).eval())
print('Correct event was in top three prediction:', top_k_categorical_accuracy(y_test,prediction, k=3).eval())
All things held equal you should get similar accuracy metrics.

So, the model is predicting the next event correctly about 56% of the time. But if we returned the top three next best actions we’d be correct about 98% of the time!
6. Generate Events
Last but not least it would be nice to create some actions. This can be done pretty easily using model.predict and then using our event mapping that was setup during Step 1.
# Create predictions prediction = model.predict(X_test) # Map to events events[np.argmax(prediction[1])]
Our second prediction is telling us that it’s time to get the commercial documents signed!

And there you have it, a fully worked example showing you how to take historical sales activity data and generate predictions for the next best step. To summarise you preprocessed your data, reshaped it into sequences and threw it into a LSTM model to start predicting!
This shows how to complete the task using sales data but the possibilities are endless. I built this model using Watson Studio, in case you haven’t used it before, you should! It’s an awesome, all-in-one data science studio! Check it out here> Watson Studio.