Picture this.
You just started a business.
You sunk a heap of money into it.
You poured your heart and soul into producing a product
You shed blood, sweat and tears into build your team and delivering great service.
But…
You’re still getting sucky reviews on Yelp.
WHYYYY!!!!???!!!
Maybe, there’s a pattern you’re not seeing. Maybe, you’re spending too much time reading the good reviews and not surgically breaking down the negative ones.
I get it. It takes time. And when you’re running a new business, you just don’t have much of it lying around.
So here’s another solution.
What if, you could throw your reviews into a black box and out popped out some intelligent insights. Insights, that could help you drill into reviews that maybe weren’t so great.
You’re. In. Luck!
This post goes through exactly how to do just that. Taking your raw reviews from a site like Yelp and leveraging modern Natural Language Processing tools to get clear and useful metrics around sentiment.
Let’s jump right in.
Step 1 – Getting Data
Got data? Good. If not, meh, we can work with that.
There’s a few different ways you can get access to your business reviews. If you’ve got them collated somewhere already that’s perfect. Throw them all into a Excel Workbook or a CSV. You can then load it up in Step 2. To load your data use the pandas from_csv method.
If not…and your business (or the business you want to analyse) has reviews on Yelp, Facebook Reviews or Google places you can build a quick scraper to get this data into a format that you can use.
You can use the python Requests module to make a request to the website where the reviews are located and then use BeautifulSoup to traverse (read search through) the result to extract what you need.
To do this, first start out by import the required modules.
# Import Requests import requests # Import Beautiful Soup from bs4 import BeautifulSoup
Then make a request to a the site that contains the reviews you want to extract. In this case, the url used points to Tesla dealerships on yelp.
# Execute request
# If you’re using a different site just replace the url e.g. r=requests.get(‘put your url in here’)
r = requests.get('https://www.yelp.com/biz/tesla-san-francisco?osq=Tesla+Dealership')
You can check that your request was successful by checking the request status code. If the function returns 200, that means that the request has executed successfully.
# Check request status print(r.status_code)
If this returns anything other than 200, check that the url you’ve got is valid and correctly formed.
Assuming that all went well and you’ve got a status code of 200, you can view the result by accessing the text attribute of the request.
# Check result r.text
This should return the raw HTML code from the website.

Beautiful Soup makes it easier to scan the result and extract data based on patterns from the website. By converting the request result to a BeautifulSoup object (aka making the soup) its going to make your life a helluva lot easier to get out what you need.
# Make the soup soup = BeautifulSoup(r.text, 'html.parser')
Now if you inspect the reviews from the actual web page.
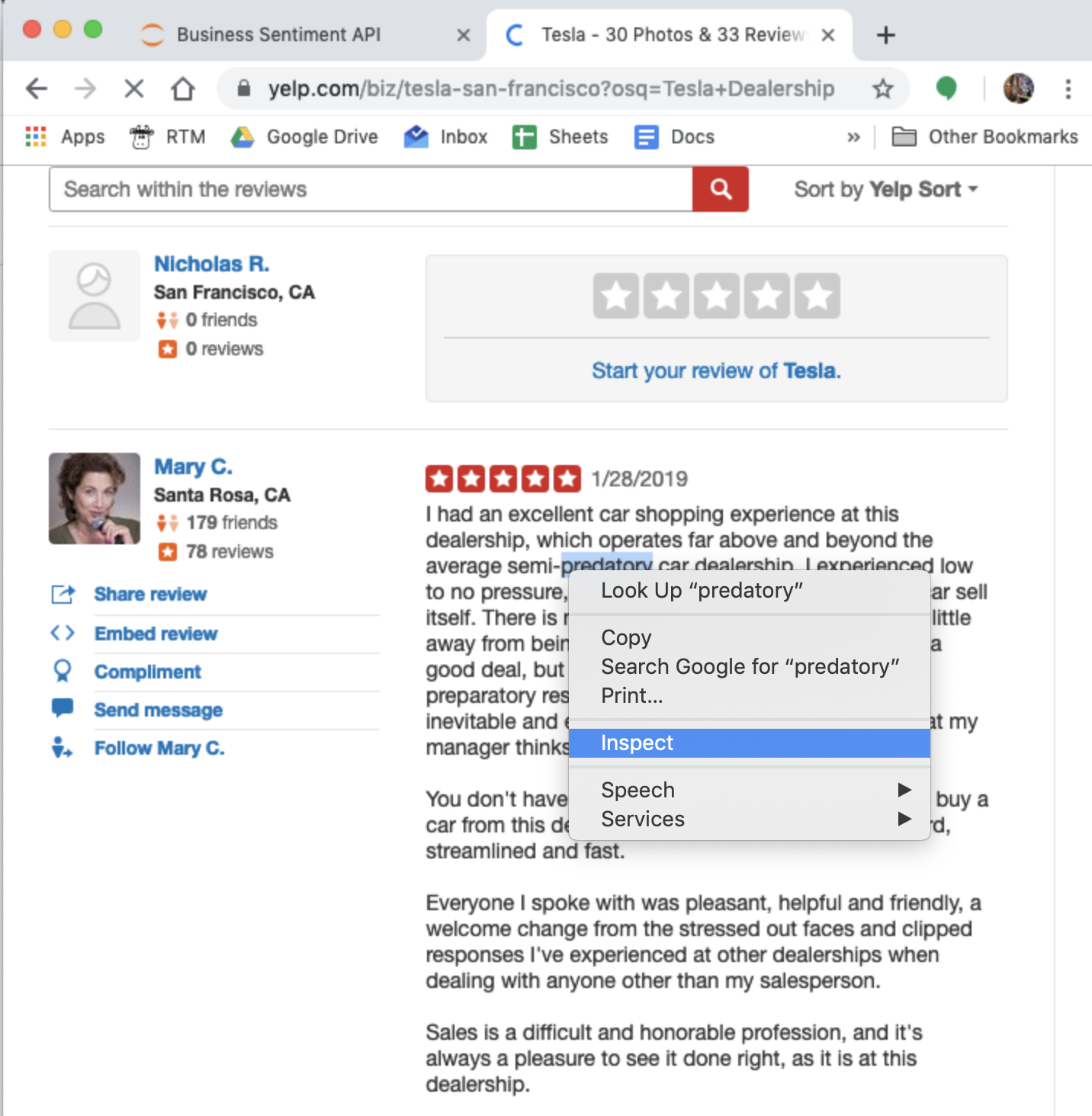
You’ll notice that all the reviews are actually encapsulated in paragraph tags inside a div called ‘review-content’.
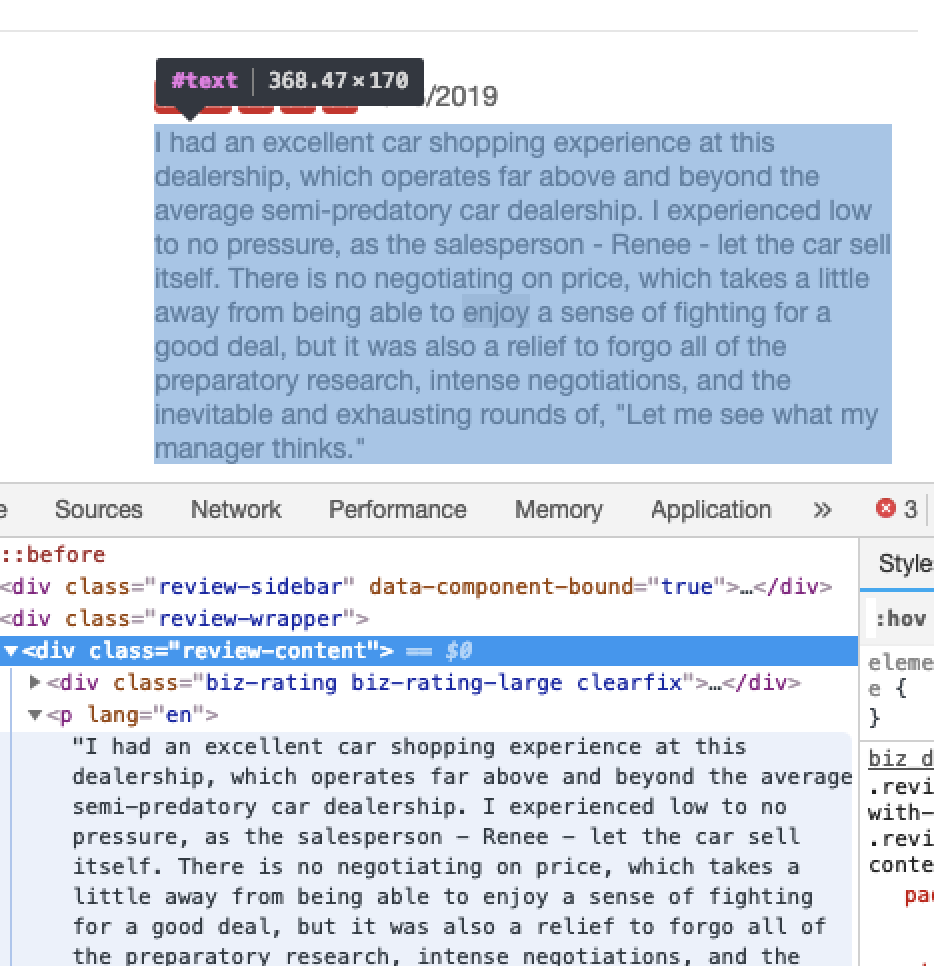
This is great because you can use this pattern to extract the paragraphs from these divs using the findAll and find methods.
# First get all of the review-content divs results = soup.findAll(class_='review-content')
This should return all of the divs that have a class of ‘review-content’.
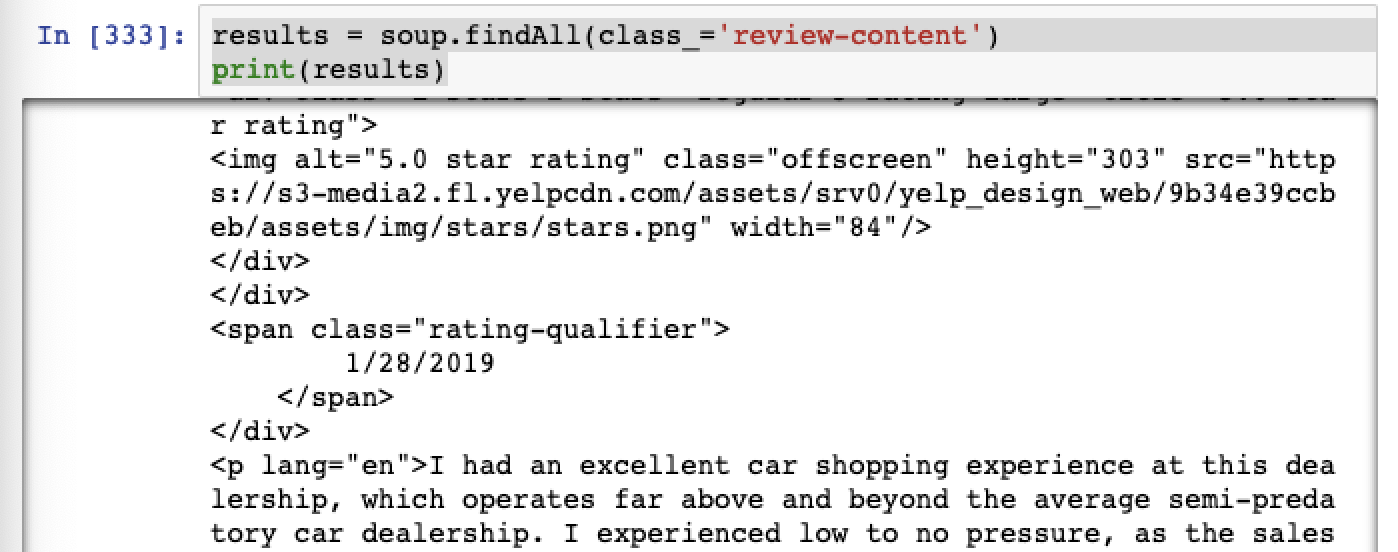
Then you can loop through each div found and use the find function to get every paragraph and store it in a list.
# Loop through review-content divs and extract paragraph text
reviews = []
for result in results:
reviews.append(result.find('p').text)
What you should have left is a list that contains each individual review and none of the messy residual HTML.

This gets us to the point where you can now start analysing and cleaning the data set.
Step 2 – Analysing the reviews
Sidebar: If you’re not interested in analysing the data set you can skip this step completely and head straight to step 3.
To make life easier, let’s take the reviews and convert them into a dataframe. For that you’ll need to import pandas and numpy.
# Import pandas import pandas as pd #Import numpy import numpy as np
Then create a dataframe out of the reviews list that you created in step 1.
# Create a pandas dataframe from array df = pd.DataFrame(np.array(reviews), columns=['review'])
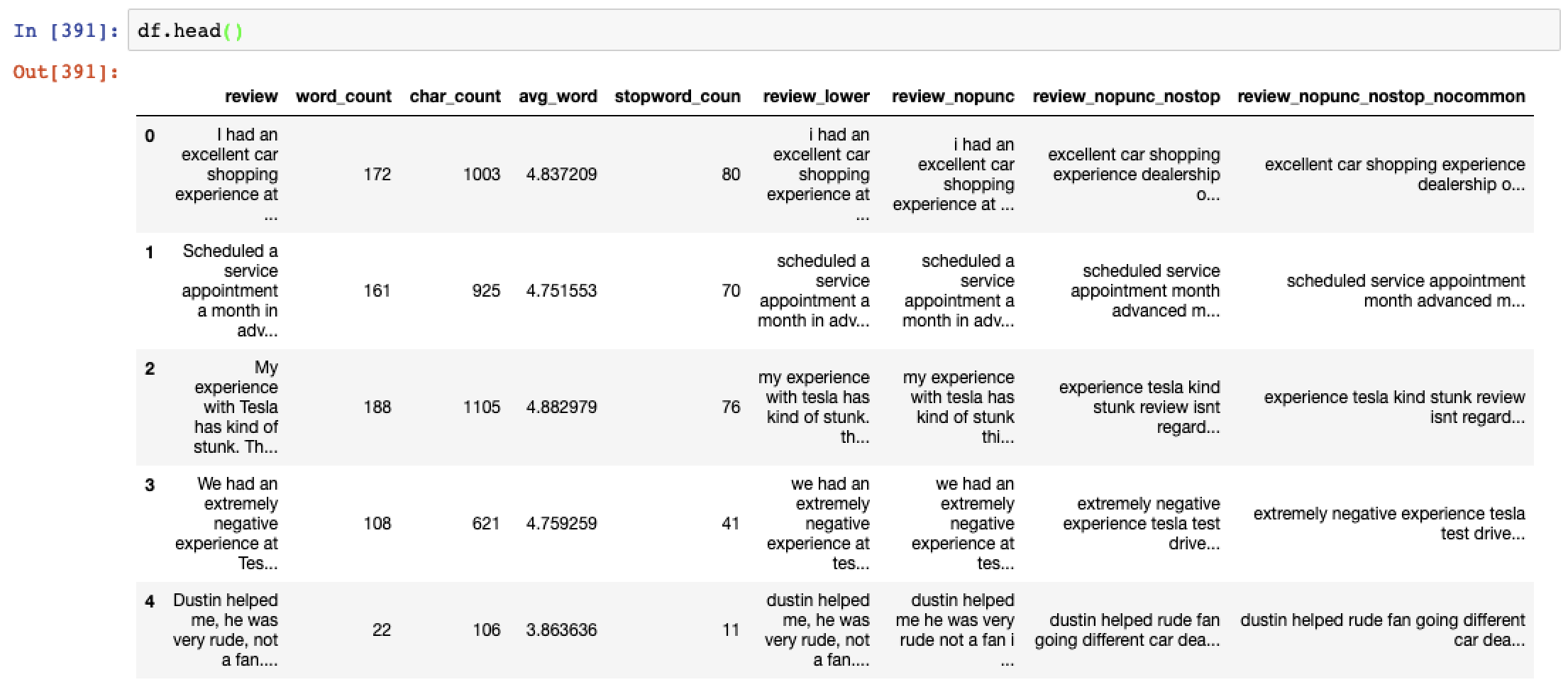
We’re going to calculate four metrics in total for each review:
- Word Count – total number of words in each review
# Calculate word count
df['word_count'] = df['review'].apply(lambda x: len(str(x).split(" ")))
- Character Count – total number of characters in each review
# Calculate character count df['char_count'] = df['review'].str.len()
- Average word length – the average length of words used
def avg_word(review): words = review.split() return (sum(len(word) for word in words) / len(words)) # Calculate average words df['avg_word'] = df['review'].apply(lambda x: avg_word(x))
- Stopword Count – total number of words which are considered stop words
# Import stopwords from nltk.corpus import stopwords
# Calculate number of stop words
stop_words = stopwords.words('english')
df['stopword_coun'] = df['review'].apply(lambda x: len([x for x in x.split() if x in stop_words]))
We can then review the summary statistics
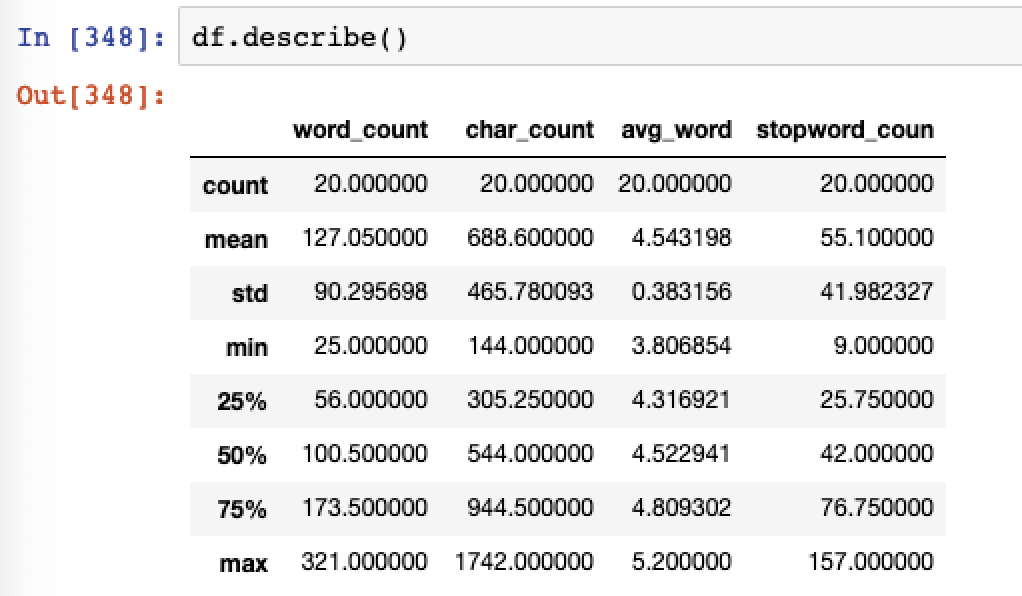
And also review the metrics per review.
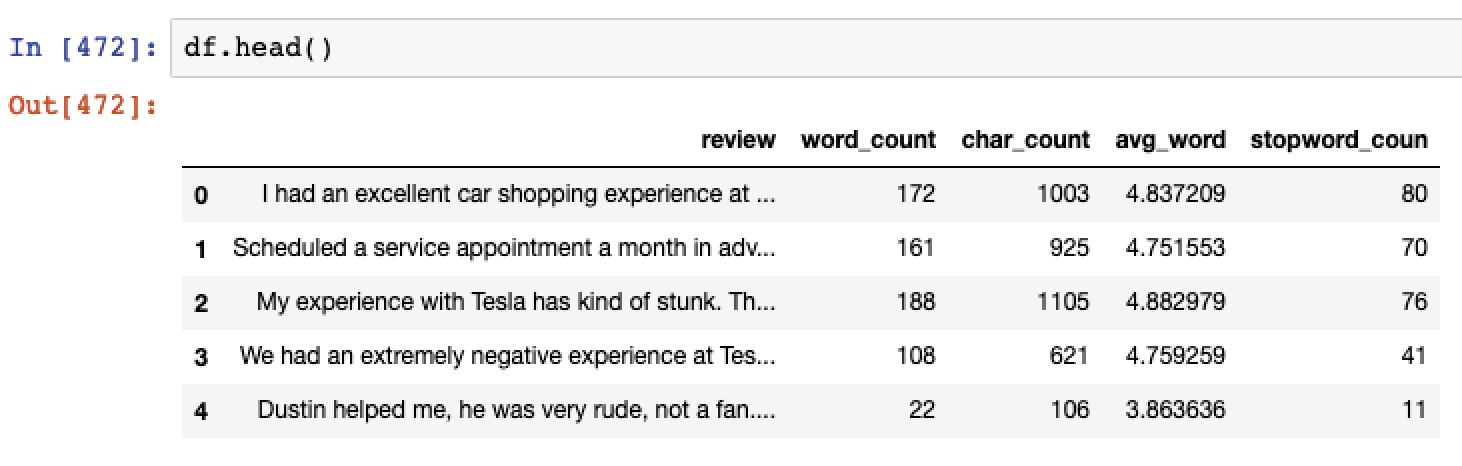
Step 3 – Cleaning the data set
How does the old saying go?
Crap In, Crap Out.
Well the same applies to natural language processing and sentiment analysis. Cleaning text is a little different to regular data cleaning in that, well, you’re dealing with strings of text rather than records of data. Regardless, cleaning the data is still important. The four most common steps that are performed are;
- Lowercasing all words
- Removing punctuation
- Removing stopwords
- Removing trivial words (excessively short and frequent words e.g. A, I, us)
Performing these steps ensures that the text is as relevant as possible to the message that the actual review is trying to represent.
Without further adieu, let’s get cleaning.
First up, lowercasing all the words. The stop word list that is used in a couple of steps has all of the words in lowercase, by lowercasing all of the text in the reviews it means that words which are capitalised won’t be missed.
For example capital I isn’t evaluated as being in the stop word list whereas the lowercase representation is.

# Lower case all words df['review_lower'] = df['review'].apply(lambda x: " ".join(x.lower() for x in x.split()))
A key part of text analysis is tokenization, this is where blocks of text are split into their individual words and pieces of punctuation. The punctuation itself does not add much meaning when searching for a topic or trying to ascertain sentiment, hence its best to strip it out.
# Remove Punctuation
df['review_nopunc'] = df['review_lower'].str.replace('[^\w\s]', '')
Stop words are commonly occuring words, that hold little to no meaning.
Given they hold little meaning, removing stop words is common practice in natural language processing. The good news is, you don’t need to define your own list of stopwords for natural language processing. The Natural Language Toolkit comes built in with a pretty comprehensive stop words list that you can leverage.
# Import stopwords
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# Remove Stopwords
df['review_nopunc_nostop'] = df['review_nopunc'].apply(lambda x: " ".join(x for x in x.split() if x not in stop_words))
Last but not least, removing trivial words. This step is not super important as reviews tend to be quite short blocks of text but nonetheless it’s good practice to remove redundant data when we’re performing any analysis.
Start off by reviewing the 30 most commonly occuring words that remain after removing stopwords.
# Return frequency of values
freq= pd.Series(" ".join(df['review_nopunc_nostop']).split()).value_counts()[:30]
If you’re using the same dataset, you should get something that looks a little like this.

Based on words that you’re seeing, you can create a list of those that aren’t adding much meaning. In this case, there are a few that are probably worth removing, these can be added to a new stopwords list.
other_stopwords = ['get', 'us', 'see', 'use', 'said', 'asked', 'day', 'go' \ 'even', 'ive', 'right', 'left', 'always', 'would', 'told', \ 'get', 'us', 'would', 'get', 'one', 'ive', 'go', 'even', \ 'also', 'ever', 'x', 'take', 'let' ]
And removed from the review text block.
df['review_nopunc_nostop_nocommon'] = df['review_nopunc_nostop'].apply(lambda x: "".join(" ".join(x for x in x.split() if x not in other_stopwords)))
This should leave you with a data frame with reviews at each of the different stages of cleaning. We’ll eventually drop these and replace them with our final sentiment metrics so don’t fret if it looks a little messy for now.
Step 4 – Lemmatize The Reviews
Lemmatization is the process of transforming your natural text from english to lemming language.
I kid, it’s the process of translating words back to their base form.
Lemmatization Example
- am, are, is would be lemmatized to be
- car, cars, car’s, cars’ would be lemmatized to car
This cuts out the number of words that are available for analysis by combining similar forms into one base form. One of other processes that is commonly used to cut down the the number of unique words in natural text processing is a process called stemming.
Stemming shortens the number of unique words by removing common endings.
Example:
- Caresses is stemmed to caress
- Ponies is stemmed to poni
Some words can stand alone without the extended ending however as shown with the word ponies above, this is not always the case. In this case we’ll use lemmatization to shorten down our word lsit.
The text blob module provides a simple method to lemmatize the reviews.
# Import textblob from textblob import Word # Lemmatize final review format df['cleaned_review'] = df['review_nopunc_nostop_nocommon']\ .apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
This is an example of the change from base review to clean and lemmatized review:

Step 5 – Sentiment Analysis
Finally, onto the sentiment analysis.
After all that cleaning actually performing the sentiment analysis is really quite straight forward. The textblob module again comes in quite handy for this task and returns not only sentiment metric but also a subjectivity metric as well.
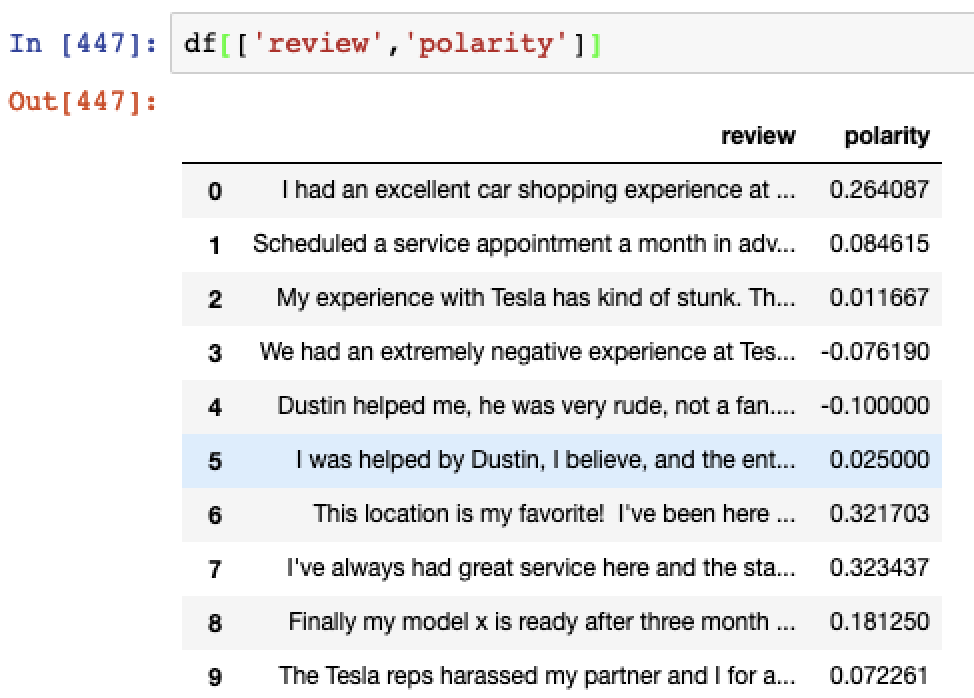
The polarity metric refers to the degree to which the text analysed is positive or negative, between a range of -1 to 1. A score of 1 means highly positive whereas -1 is considered well and truly negative.
# Calculate polarity from textblob import TextBlob df['polarity'] = df['cleaned_review'].apply(lambda x: TextBlob(x).sentiment[0])
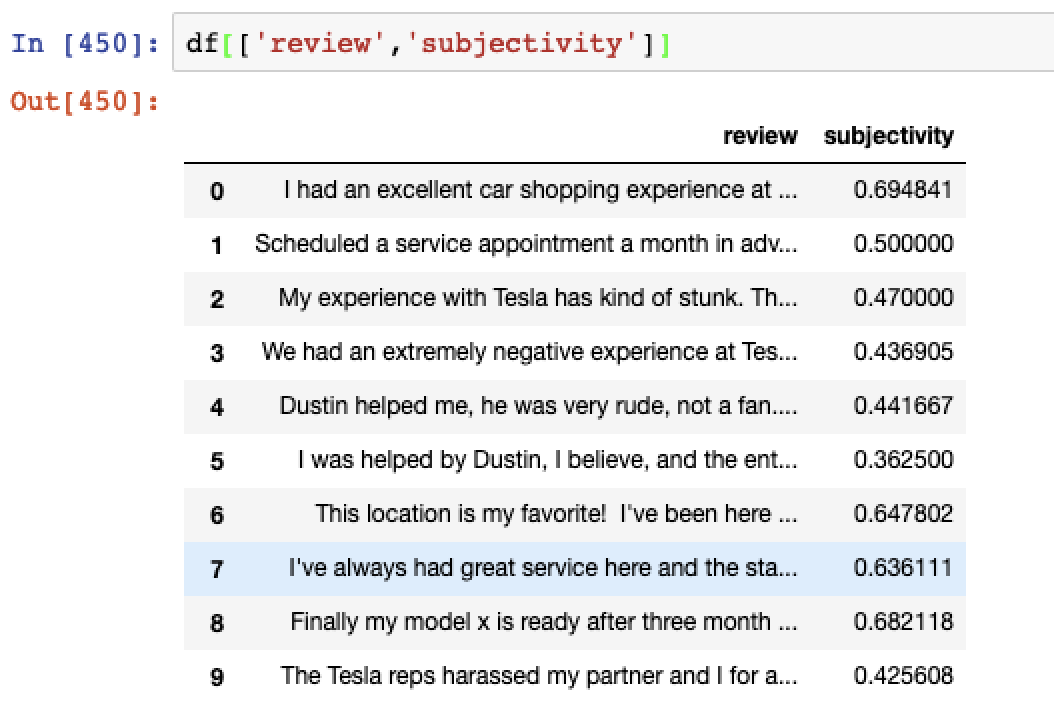
We can also analyse subjectivity, this is the degree to which the text analysed relates to personal emotion or factual information between a scale of 0 to 1. With scores closer to one indicating a higher level of subjectivity and being based mostly on opinion.
# Calculate subjectivity df['subjectivity'] = df['cleaned_review'].apply(lambda x: TextBlob(x).sentiment[1])
And that’s it, from start to finish how to better analyse sentiment and sift through reviews of your business! Have a question? Got stuck? Struggling to start? Leave a comment below!
Other Resources
Ultimate guide to deal with Text Data (using Python)