Okay. That’s it. I’ve finally got my dashboard setup. Everything is perfect. My boss can start on this page to get a summary of what’s been happening. Then they can drill through to here to get lower level analysis and see commentary.
Now, if only I could get that last slice of data so they can see Sales by Region AND by Sales Rep. That should be easy enough to get. Just grab it fro–
Ughhh, it’s not a dimension.
Getting the features right in a data solution can spell victory or failure. There’s a whole heap of work that goes into getting to that elusive end state. You know the one. Users have all the data they want and need. All the data points are perfectly reconciled. Feeds are updated in real time. Analysts can drill through to transactions in the blink of an eye.
Ahhh utopia.
It takes teams of skilled data wizards to get there. They’re masters of data transformation. They can get data from database A to B without a hassle. How are these data wizards created you ask? It comes from experience…or from learning a ridiculous amount about data engineering.
Data engineers for lack of a better word are the people who collect, transform and store your data, sort of like database techies but with new and improved skills. They’re in ridiculous demand at the moment. Why? Without accessible data, doing amazing things like algorithm training, deep learning and visualization become infinitely harder. Want the fast path to becoming a data engineer? Check out the steps below!
Super Fast Theory

Before actually delving into any new endeavor, it’s usually a good idea to get an overall picture of how things fit together. Understanding some of the key ideas helps set the scene for all the things to come.
- Dataconomy Big Data Dictionary
- Udacity Introduction to Relational Databases
- Kimball Lifecycle in a Nutshell
Databases (How to Setup Databases to Store Data)
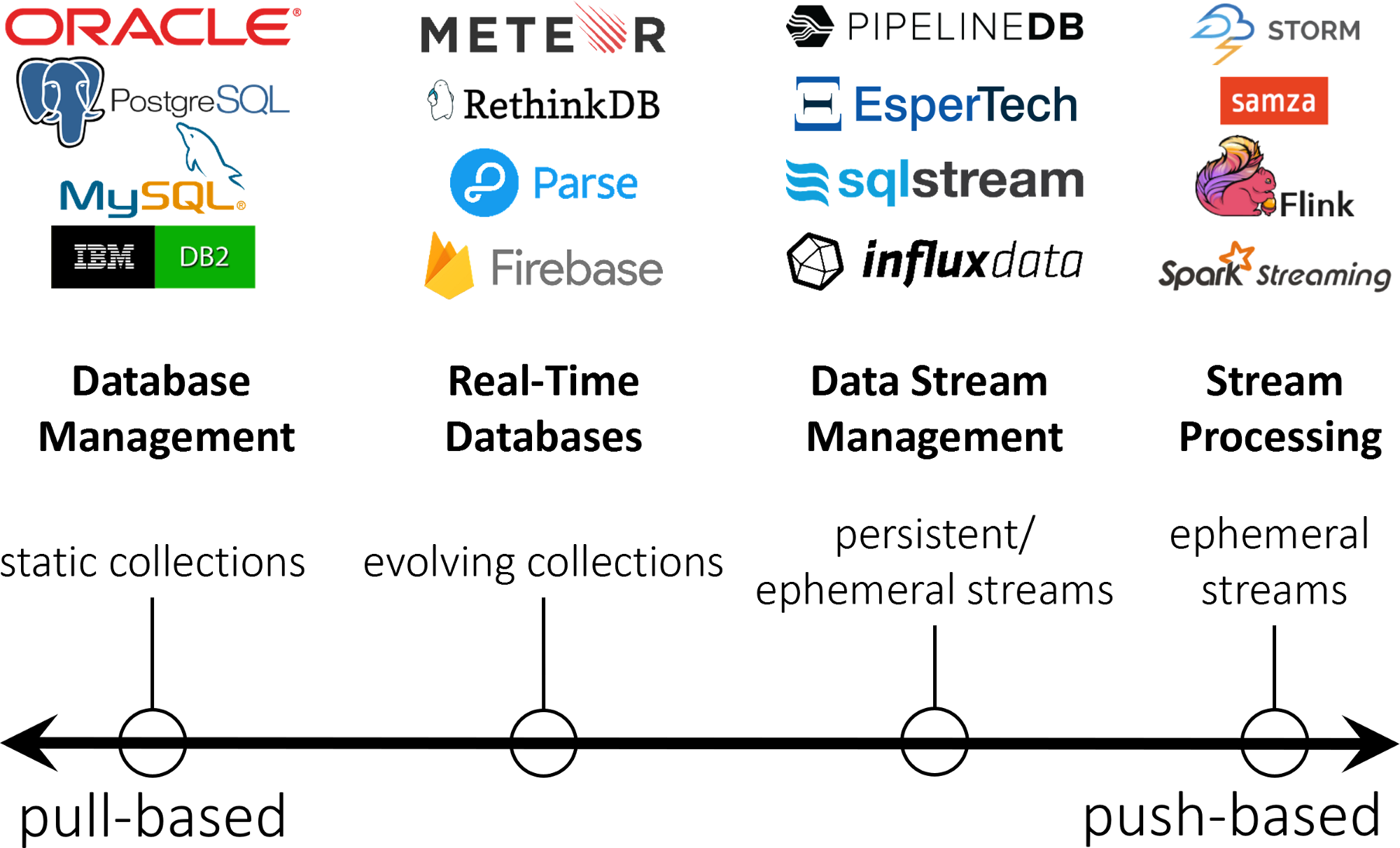
Repeat after me, Excel is not a database. Okay, I’ll come out here, I’ve definitely stringed together giant Excel workbooks to get stuff done before. They’re flexible and allow you to do it, so why not right? Well, as soon as you get past 1,048,576 rows of data you’re going to run into trouble. This is where databases come into play, they allow you to store potentially infinite amounts of data and access it (relatively) quickly.
- Dataversity Review of Database Types
- Full Stack Academy NoSQL vs SQL: a Database Tutorial
- Amazon Setup an Amazon RDS (MySQL Database)
- How to setup an Amazon DynamoDB (NoSQL Database)
- How to Setup a Microsoft SQL Data Warehouse
- How to Setup an Azure Data Lake Store
- How to Setup Google BigQuery
- How to Setup an IBM DB2 Database
- How to Setup Oracle Databases on Various Platforms
- How to Setup a SAP Hana Database
ETL (How to Get Data in The Right Format and Load)

Now that you’ve got your database setup, how do you get the data into it? In order to get data into your database or data warehouse you need to use a process called ETL. ETL standard for Extract, Transform and Load. It’s widely accepted as
Vendor Specific
- IBM DataStage Beginner Tutorial + Documentation
- Create a Project and Package with Microsoft SSIS
- SAP Business Objects Data Services Beginner Tutorial
- Oracle Data Integrator Tutorial Series
Pure ETL
- Informatica PowerCenter Beginner Tutorial
- KNIME Online Self Training
- Clover ETL
- Talend Open Studio Tutorial For Beginners
So, you’ve got your data stored. Now what?
You need to get it back out.
When you’re loading data into a database you typically store raw or transactional data. The data volumes are HUGE (think terabytes to petabytes) and as a result, are usually stored on disc. This, however, means that it’s relatively slow to get back out for analysis. The main way around this is to load the required data set into memory for high-speed analysis. This process, selecting and reshaping the data that is needed into a useable format is referred to as modeling. You could also lump this into the transformation phase of ETL, but I’ve lumped it separately because it’s typically handled separately.
Modelling
These are two of my favourite tools. They allow you to take relational (flat) data and convert it into a multi-dimensional array. Rather than storing data in a table these tools create cubes so that data is stored at a cross section. It makes it ridiculously easy for business users to interrogate information as it’s readily presented in an easy to consume format.
Querying
It’s also a good idea to understand how to query data from your database or model. The following two links go over the most common method using SQL (Structured Query Language) and MDX for querying multi-dimensional models.
Distributed Computing
The other way to increase the speed of your information is to use distributed computing. This is a fancy way of saying, split up my data and process it over multiple computers. So, rather than storing or processing all of your information on a single server you can split it up onto multiple computers and effectively spread the load.
MapReduce and Spark are the two dominant packages/libraries that are leading the way in this field. Spark is faster, but it’s a good idea to get to get an understanding of how the process works to begin with.
- What is MapReduce?
- What is HDFS?
- Cognitive Class Introduction to Hadoop
- Cognitive Class What is Spark?
- Apache Kafka Quick Start Guide
- Spark Streaming Documentation
API and Connectors
The greatest value that a data engineer brings to the table is the ability to make data accessible. For this reason, APIs and Connectors are ridiculously useful. Getting a good handle on how to collect and connect data will make everything a whole lot easier especially when it comes time to ‘hook up’ your data to a visualisation tool.
Overall Programs
Whilst I was doing research for this article, I found some really useful ‘overall’ programs to get you started on data engineering. These don’t cover all vendor specific instructions but do allow you to get a good overall handle on the main parts of data engineering. The Microsoft Professional Program is (as you might have guessed) Microsoft aligned, whereas Cognitive Class was released by IBM. The Insight Engineering Fellows Program is not online but from what I’ve heard is a brilliant opportunity if you can attend.
Microsoft Professional Program
Insight Engineering Fellows Program
Ready to get your engineering underway? Start out by reading the Dataconomy Big Data Dictionary and keep going from there. Once you’ve got a good handle on these concepts start creating databases and loading data. Kaggle is a good place to get datasets in case you don’t have any lying around! Go for it!
Liked this article? Share it with a friend who wants to get involved!