It’s everywhere around you. It’s crept into every part of your life. It’s crucial to your work. It controls what you’re allowed to do. It’s how you learn. There’s a super high chance that it’s on your clothes right now.
It provides so much meaning in our lives but we often take its importance for granted.
Text.
Something which comes so easily to us as humans isn’t exactly straightforward for computers to understand.
But it can be trained.
These projects walk you through practical implementations of text mining, processing, and comprehension using freely available repos on Github. The first section goes through how to use repos from Github and what to do to get the code to run.
Don’t fret if you have no idea what Github or a repo is…I’ll walk you through it.
How to run these projects yourself!
This first section goes through how to run code from a Github repo. If you’re comfortable doing this yourself, feel free to skip this section.
1. Read the Markdown
Think of the markdown file as the developer’s instructions. They usually provide background on the code, how to run the app and any dependencies. It’s usually a good idea to have a quick read before you attempt to run the code.
The markdown file is usually labeled README.md and displayed in repository (repo) file structure. For the first example, go to the Github link and open the markdown file.
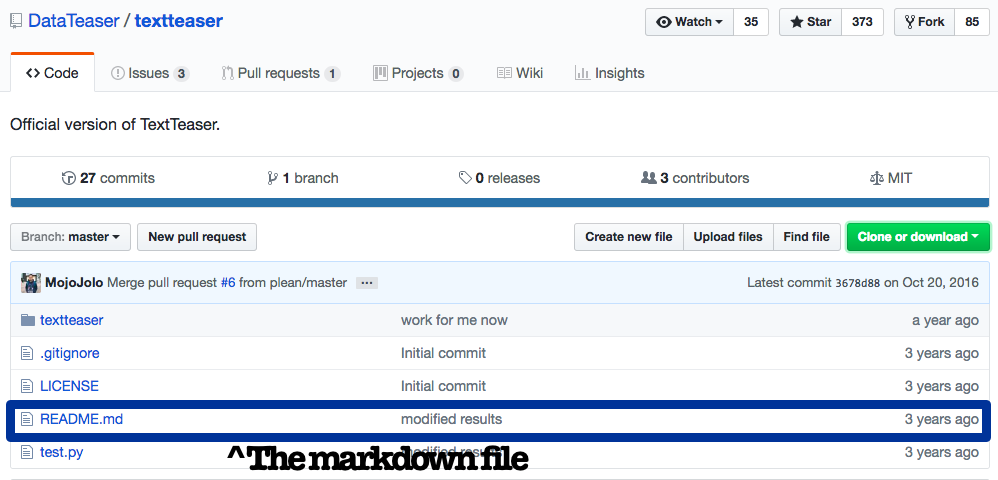
Follow the install commands that are in the markdown file when attempting to run the code for the first time. If you’ve already installed the dependencies you shouldn’t have to do this again.

In this case, we would run the following commands using our terminal.

2. Install Dependencies
Before actually running any commands it’s important to make sure we have the required packages installed. In this case, the instructions are under Installation. Typically the easiest way to install the package is to use Python Package Index (pip) assuming your package is Python related. (Side Note: In this example, you’ll need to skip forward to the next step to clone the repo before installing dependencies. This is because the dependencies are stored in a text file called requirements.txt)

3. Clone Package and Follow Run Steps
The first command is;
git clone https://github.com/DataTeaser/textteaser.git
This will download a copy of the code to our local machine.
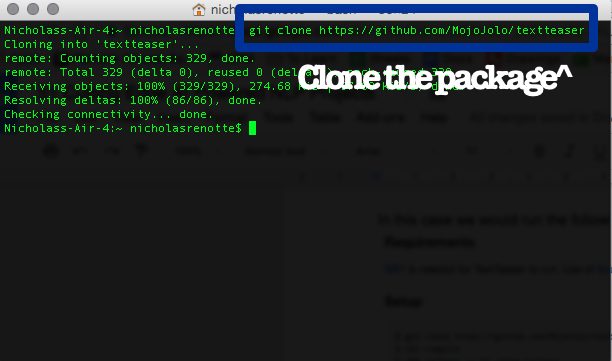
Once you’ve cloned the package. Just follow the run steps included in the markdown. In this case, we’ll start with the install and then run the test script.
#go into the textteaser directory >>>cd textteaser #then installing the packages >>>pip install -r textteaser/requirements.txt #then runn the test code >>>python test.py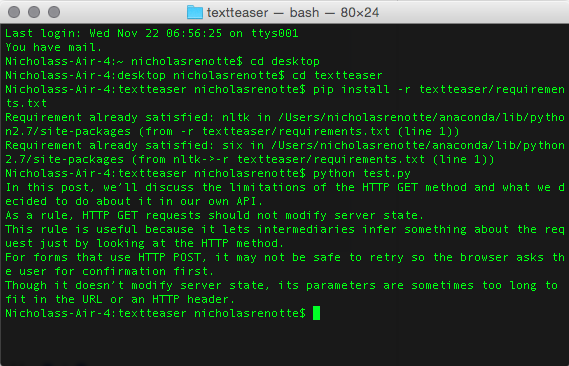
And that’s it, you just ran your first code repo from Github. Right, onto the projects….
Text Summarisation
Text Teaser
Couldn’t quite get the hang of speed reading? Textteaser summarises documents so that you only need to focus on the key parts.
Sumy HTML Summariser
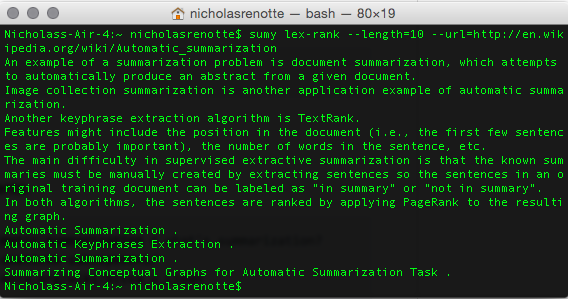
The Sumy HTML Summariser library can be easily imported into your python code to summarise information pulled from HTML pages. It can also be used via command line by passing through the right parameters like so:
$ sumy lex-rank --length=10 --url=http://en.wikipedia.org/wiki/Automatic_summarization
This example returns a summary of the Automatic Summarisation article from Wikipedia.
Chatbots
Chatterbox

Chatterbot allows you to build chatbots natively using python ridiculously quickly. It’s simple to get started and the readme provides a lot of background on how to get up and running..
Watson
Build a chatbot using the Watson API. There are a whole bunch of install procedures available however it’s probably easiest to run off the local machine installation procedures the first time.
Android Chatbot
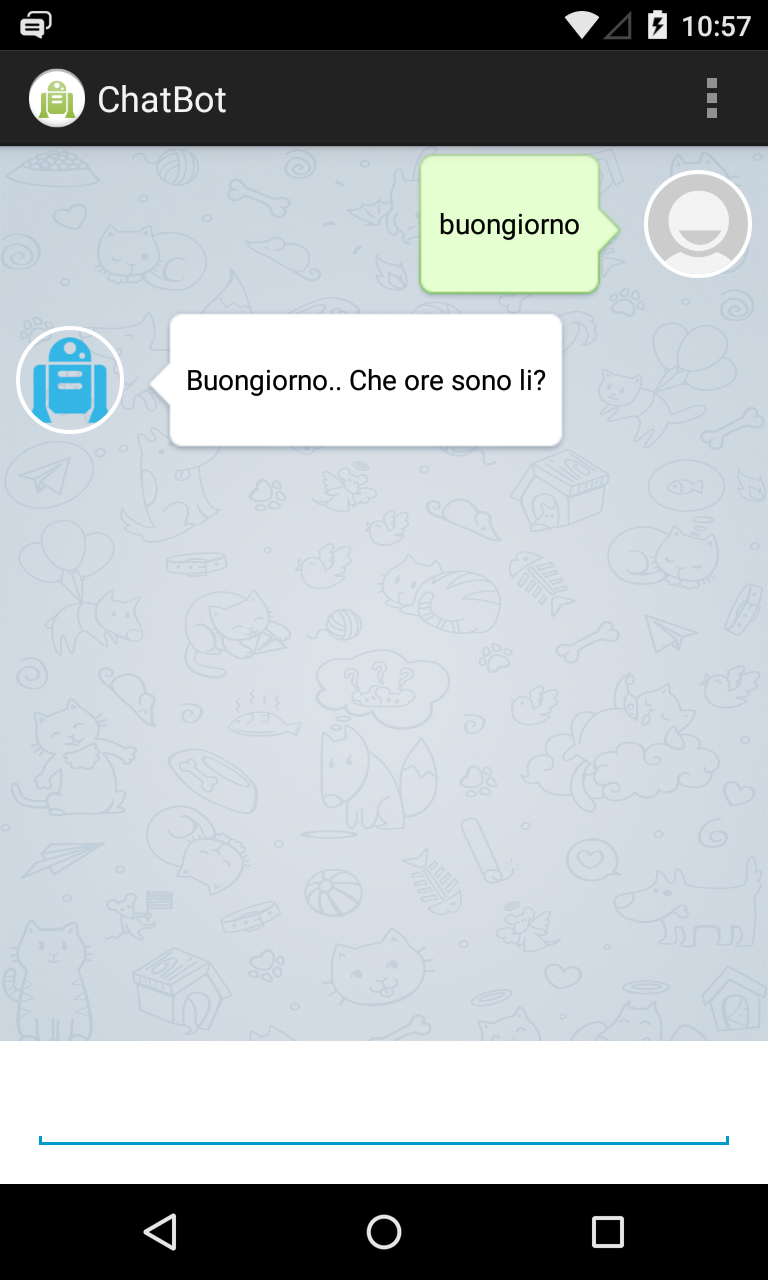
Keen on developing mobile apps? This repo shows you how to create an Android chatbot using A.L.I.C.E.
Sentiment Analysis
VADER Sentiment Analysis

VADER or Valence Aware Dictionary and sEntiment Reasoner for long allows you to analyse sentiment. It’s been specifically developed to pick up on sentiment and tone typically expressed on social media, for this reason, it’s the perfect tool for Twitter analysis.
Text Processing
Tacotron Text to Speech
Keen on converting your text to speech? Say no more. Tacotron is here. This example uses Tensorflow to convert text to speech. You heard right, pass through text and it’ll read it out. On the plus side, it’s a whole heap better than typing words into Windows Speech Recognition.
Google Tensorflow Translator
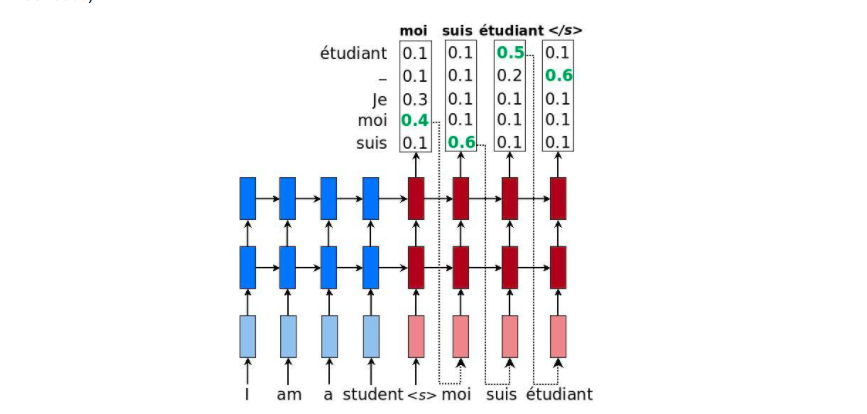
Google code repos seem to be the gold standard on Github (go figure). This example doesn’t fall short. The Google Tensorflow Translator is an example of Neural Machine Translation or NMT for short. The model itself uses an encoder-decoder architecture to translate the input into the another specified language.
Text Generators
Neural storyteller

This one is awesome. The neural storyteller generates short little stories based on the pictures that you feed it. There’s an example of this above and more on Github. You can train your model on different corpus’ to generate alternate styles of writing.
Text to Images

You heard right. This demo creates images based on the text phrases that it’s passed. does this using captions created based on Skip Thought Vectors and generates images using conditional Generative Adversarial Networks.
RNN Text Generator

Ready to create the next Harry Potter series? This RNN generator allows you to create text based on a trained library. In this example, ML Master Trung steps through how to use recurrent neural networks to train, test and generate text using the Harry Potter corpus.
Social Media Analysis
Text Mining Using Twitter Streaming
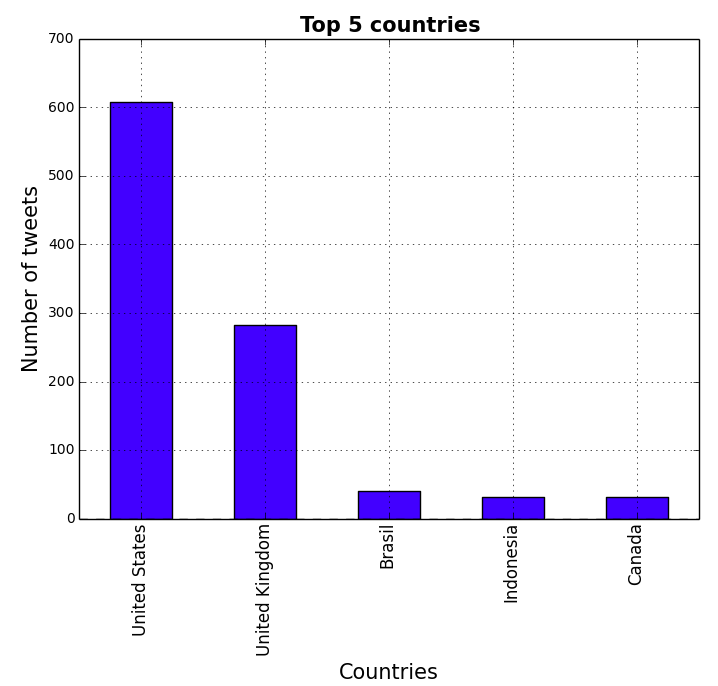
Interested in twitterlytics? Try this out. The tutorial shows how to get twitter insights using the Twitter API. There’s a full walkthrough available here.
Pick a project and try it out! If you get stuck feel free to drop a comment below. Otherwise, StackOverflow is your friend!